Un controller est un programme qui exécute en continu une boucle de contrôle infinie (control loop). Il observe l’état actuel et l’état désiré des objets Kubernetes. Si une différence est détectée, le controller agit pour rapprocher l’état actuel de l’état désiré.
Concept clé
Dans Kubernetes, les controllers sont des boucles de contrôle qui surveillent l’état de votre cluster et effectuent, ou demandent, les modifications nécessaires. Chaque controller tente de rapprocher l’état actuel du cluster de l’état désiré.
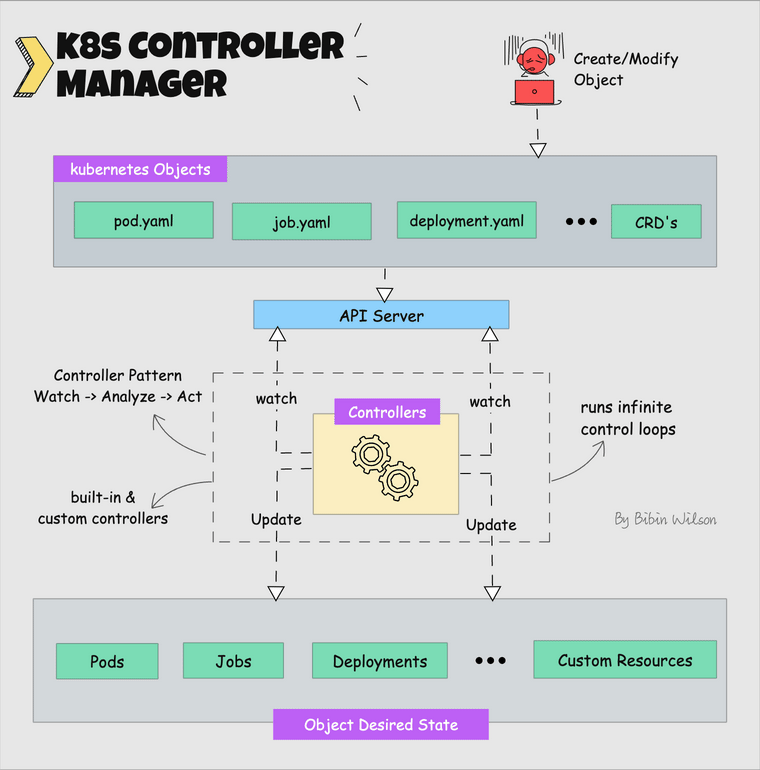
Exemple concret
Vous déclarez un Deployment avec un manifeste YAML indiquant l’état désiré (exemple : 2 réplicas, montage d’un volume, configmap, etc.).
- Le Deployment Controller intégré s’assure que cet état est maintenu constamment.
- Si vous modifiez le déploiement à 5 réplicas, ce controller détecte le changement et agit pour qu’il y ait effectivement 5 réplicas.
- Auto-réparation : si un pod meurt ou qu’un nœud part en panne, le controller crée automatiquement de nouveaux pods pour garantir la disponibilité voulue.
| Composant | Rôle dans la création des pods |
|---|---|
| kube-controller-manager | Gère les contrôleurs qui créent/modifient les ressources Pod en respectant l’état désiré |
| kube-scheduler | Assigne un pod à un nœud adapté |
| kubelet | Sur le nœud worker, démarre effectivement les conteneurs du pod |
Le kube-controller-manager ne “crée pas” les pods dans le sens d’exécution, mais il crée les objets pods dans l’API Kubernetes pour que le système les prenne en charge et les maintienne.
Rôle du Kube Controller Manager
| Fonction | Description |
|---|---|
| Gestionnaire central | Gère tous les controllers Kubernetes (comme Deployment, ReplicaSet, Job, Namespace, Node, etc.). |
| Contrôleurs multiples | Chaque controller est responsable d’un type spécifique d’objet Kubernetes. |
| Intégration avec le Scheduler | Le scheduler est aussi un controller géré par le Kube Controller Manager (mais le kube-scheduler ne fait pas partie du kube-controller-manager). |
| Extensibilité | Supporte les controllers personnalisés associés à des définitions de ressources personnalisées (CRD). |
Liste des principaux controllers intégrés
| Controller | Fonction principale |
|---|---|
| Deployment Controller | Gère le cycle de vie des Deployments : s’assure que le bon nombre de pods est en cours d’exécution |
| ReplicaSet Controller | Maintient le nombre souhaité de pods identiques pour l’échelle et la disponibilité |
| DaemonSet Controller | Garantit qu’un pod spécifique s’exécute sur chaque nœud (ou certains nœuds sélectionnés) |
| StatefulSet Controller | Gère les applications nécessitant des identifiants, du stockage persistant et un ordonnancement strict |
| Job Controller | Lance des tâches batch devant s’exécuter jusqu’à leur complétion |
| CronJob Controller | Planifie des jobs à exécuter périodiquement selon un cron |
| Endpoints Controller | Met à jour la liste des endpoints attachés à chaque service |
| Service Controller | Crée et gère les services virtuels réseau (ClusterIP, NodePort, LoadBalancer) |
| Namespace Controller | Gère la création, la suppression et la finalisation des namespaces |
| ServiceAccount Controller | Administre la création de comptes de service associés à chaque namespace |
| Node Controller | Surveille et met à jour l’état des nœuds du cluster |
| Horizontal Pod Autoscaler (HPA) Controller | Ajuste automatiquement le nombre de pods via autoscaling horizontal (CPU, mémoire, custom metrics). Voir mécanisme de KEDA. |
| Volume Controller | Gère l’attachement et le détachement des volumes persistants (PV/PVC) |
| PersistentVolumeClaim (PVC) Controller | Attribution automatique des volumes aux pods qui le requièrent |
| Ingress Controller | Gère l’accès HTTP/S externe vers les services internes (peut être natif ou tiers, selon le choix d’implémentation) |
Schéma simplifié du fonctionnement des Controllers
| Étape | Description |
|---|---|
| Surveillance | Boucle infinie qui observe les ressources via l’API server. |
| Détection d’écart | Compare état actuel avec état désiré. |
| Actions correctives | Crée, modifie ou supprime des ressources pour aligner les états. |
| Mise à jour de l’état | Rapport de l’état actuel corrigé à l’API server. |
Notes complémentaires
- Les controllers ne manipulent pas directement les ressources, mais envoient des requêtes à l’API server pour appliquer les changements.
- Les contrôleurs sont conçus pour être simples et indépendants, ce qui améliore la robustesse du cluster (si un controller échoue, un autre peut prendre le relais).
- Vous pouvez créer vos propres controllers personnalisés pour gérer des ressources spécifiques via des Custom Resource Definitions (CRD).